Spatial AI -- CV model pipeline for Zero-Shot Robotics Spatial Navigation
Preface:
In robotics, one of the challenges is teaching machines to understand and navigate the world around them without prior training on that exact environment. Imagine a robot stepping into a brand-new room and being able to map it, recognize the objects inside, and move towards a target without teleoperating. This is where spatial AI comes into play, having the robot navigate the 3D space in zero-shot.
Overview
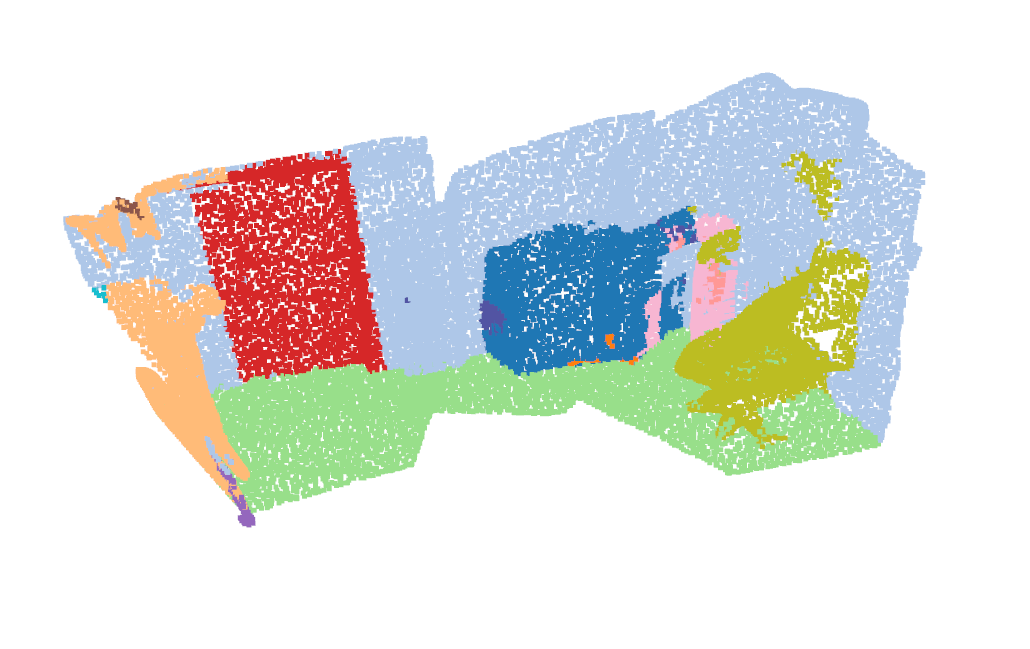
Reconstructing a 3D scene by scanning the environment is applicable in robotics simulation. VGGT: Visual Geometry Grounded Transformer achieves this by predicting scene depth directly from RGB images—without requiring known camera parameters, in a faster and inexpensive way than traditional methods like DUSt3R.
Now our repository proposes a pipeline that enables 3D scene reconstruction from one single image or a video, with a simple RBG camera predict object depth, and achieve semantic segmentation of objects in the scene. It does this by running VGGT model inference, and feeds the output into Sonata which does the segmentation. Then in the repository, we use Lekiwi robot from LeRobot Hugging Face to autonomously have lekiwi navigate to any given target object.
Our pipeline effectively works on another robots with either cartesian coordinate system, or like lekiwi with planar coordinate system with polar orientation. However, to operate on Cartesian system, some code modification needs to be carried out.

Ackowledgment: this project originally stems from my summer research/engineering internship at 1ms.AI with the help from Huggin Face LeRobot team. Great thanks to everyone.
Update: excited to have in the open source community new progress from the authors of VGGT their new updates on the model that scales in a novel way the 3D reconstruction!